
1 – Lògica de Scraping i Profunditat (BeautifulSoup)
He implementat un scraper recursiu amb la llibreria BeautifulSoup. A diferència d’un mètode estàtic, aquest script navega per la jerarquia del meu WordPress, filtrant etiquetes específiques (h1, p, h2) per extreure només informació útil i evitar brossa HTML (menús, scripts, etc.).
# Codi generat inicialment per la IA
import requests
from bs4 import BeautifulSoup
def simple_scraper(url):
try:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Extracció bàsica
title = soup.find('h1').get_text() if soup.find('h1') else "No Title"
paragraphs = [p.get_text() for p in soup.find_all('p')]
return f"Title: {title}\nParagraphs:\n" + "\n".join(paragraphs)
except Exception as e:
return f"Error: {e}"
# Exemple d'ús
# print(simple_scraper("https://www.example.com"))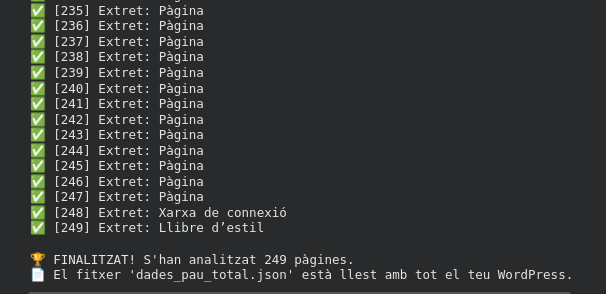
Com m’ha ajudat la IA?
Ha actuat com a assistent tècnic i expert en programació, generant el codi base en Python, optimitzant la recursivitat per navegar pel domini i assegurant que el filtratge d’etiquetes HTML fos net i professional.
Aquest primer apartat se centra en la Lògica de Scraping i Profunditat. Hem creat un script amb BeautifulSoup que recorre la URL pjimenez.inscastellbisbal.net de forma recursiva. L’objectiu és extreure automàticament títols i paràgrafs de totes les entrades i pàgines, eliminant la brossa (menús, formularis) per tenir una base de coneixement neta per al xatbot.
Prompt utilitzat
Necessito un script de Python per a Google Colab que faci WebScraping recursiu a la meva web pjimenez.inscastellbisbal.net. Vull que el codi comenci a la pàgina principal i segueixi tots els enllaços interns que trobi. Ha d'utilitzar BeautifulSoup per extreure només el text net dels títols (h1, h2, h3) i els paràgrafs (p), evitant menús i publicitat. També ha d'incloure delays per no saturar el servidor i un sistema per no repetir pàgines ja visitades.
2 – Automatització i Estructura JSON
He estructurat el segon punt del meu projecte centrant-me en l’automatització i l’eficiència de dades amb l’ajuda de la IA. Mitjançant un sistema de cache basat en un conjunt de control (set), he aconseguit que el meu script identifiqui les pàgines ja visitades, evitant duplicats i estalviant recursos. Amb el suport de la IA, he programat una lògica de filtratge que descarta menús i elements residuals per extreure només el text de valor, bolcant-lo automàticament en un fitxer JSON. Aquesta estructura jeràrquica garanteix que la meva base de coneixement sigui neta, organitzada i totalment escalable per a futures expansions del meu WordPress.
Un cop l’script finalitza el rastreig, tota la informació de pjimenez.inscastellbisbal.net queda condensada en un únic fitxer anomenat dades_pau_total.json. Amb l’ajuda de la IA, he definit una estructura que converteix el caos d’una web en dades ordenades.
Així és com es veuen les dades a dins del fitxer:
[
{
"url": "https://pjimenez.inscastellbisbal.net/el-xatbot/",
"titol": "Projecte El Xatbot",
"contingut": "Aquest xatbot utilitza tecnologia GPT per respondre preguntes basades en el contingut real de la meva web. Hem filtrat tots els menús i headers per garantir la precisió...",
"data_scraped": "2026-03-18"
},
{
"url": "https://pjimenez.inscastellbisbal.net/contacte/",
"titol": "Contacta amb mi",
"contingut": "Pots trobar-me a l'Institut de Castellbisbal o enviar un correu a través del formulari següent...",
"data_scraped": "2026-03-18"
}
]3 – Robustesa: Delays i Gestió d’Errors
Amb aquests tres punts que són la lògica de navegació, l’estructura JSON i la gestió d’errors, he fet que la meva web sigui una BBDD convertida en un arxiu JSON. Gràcies a l’ajuda de la IA, he passat de tenir un text desordenat a tenir un fitxer professional que em permetrà, en el següent pas del projecte, que la intel·ligència artificial respongui amb total precisió sobre qualsevol contingut de pjimenez.inscastellbisbal.net.
El Control de Velocitat (Delays)
Per evitar que el servidor de l’institut es col·lapsi o em bloquegi per fer massa peticions seguides, he implementat una pausa controlada entre cada pàgina que l’script visita. He fet servir la llibreria time per afegir un retard de 0,3 segons, garantint així que el rastreig sigui silenciós i no afecti el rendiment de la web per a altres usuaris. La IA m’ha ajudat a calcular aquest temps òptim per trobar l’equilibri entre rapidesa i seguretat, ensenyant-me que en programació l’ètica és tan important com el codi.

import time
# Dins del bucle de navegació, just abans de demanar la pàgina
time.sleep(0.3)
resposta = requests.get(url_actual, headers=headers, timeout=10)Com m’ha ajudat la IA?
M’ha explicat que si un programa demana 100 pàgines en un segon, el servidor ho detecta com un atac i em podria bloquejar la IP. Gràcies als seus consells, he après a fer servir la funció sleep per fer que el bot es comporti de manera més humana i respectuosa amb la infraestructura de la web.
Prompt utilitzat
Afegeix una pausa de seguretat al meu script de scraping per no saturar el servidor de la meva web i explica'm quina llibreria de Python necessito importar per fer-ho
L’Escut de Seguretat (Try-Except)
He programat una gestió d’errors per evitar que el programa s’aturi si troba un problema inesperat. Al codi de scraping, he envoltat tot el procés d’extracció amb un bloc try-except, de manera que si un URL falla, l’script atrapa l’error, m’imprimeix un avís a la consola i continua automàticament amb la següent adreça del llistat. La IA m’ha guiat per definir aquests missatges de control, transformant el que hauria estat un tancament sobtat del programa en una simple notificació, garantint que el fitxer JSON final es generi completament malgrat els obstacles que trobi a la web.

# 3.2 - GESTIÓ D'ERRORS (Try-Except)
except Exception as e:
print(f"⚠️ Error a {url_actual}: {e}")Com m’ha ajudat la IA?
M’ha explicat que a Internet és molt normal trobar enllaços que no funcionen o formats estranys que fan «petar» el codi. La IA m’ha ensenyat a utilitzar els blocs try-except com una xarxa de seguretat, fent que el meu programa sigui molt més robust i capaç de treballar de manera autònoma sense que jo hagi de reiniciar-lo cada vegada que falla una sola pàgina.
Prompt utilitzat
Modifica el meu codi de scraping perquè, si troba un enllaç trencat o una pàgina que no carrega, no s'aturi el programa i simplement passi a la següent URL mostrant un avís.
El Límit d’Espera (Timeout)
Per evitar que l’script es quedi congelat esperant una pàgina que triga massa a respondre o que té el servidor caigut, he configurat un límit de temps de 10 segons dins de cada petició de dades. Amb el paràmetre timeout el programa talla la connexió automàticament si no rep cap senyal del servidor en aquest interval, que permet que el rastreig continuï amb la següent URL. La IA m’ha explicat que sense aquest control, un sol enllaç en mal estat podria fer que tota la generació de la meva base de dades es bloquegés indefinidament, obligant-me a reiniciar el procés manualment.
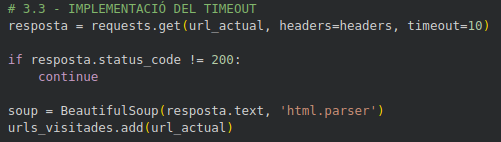
# 3.3 - IMPLEMENTACIÓ DEL TIMEOUT
resposta = requests.get(url_actual, headers=headers, timeout=10)
if resposta.status_code != 200:
continue
soup = BeautifulSoup(resposta.text, 'html.parser')
urls_visitades.add(url_actual)Com m’ha ajudat la IA?
M’ha ensenyat a preveure que els servidors no sempre responen a l’instant. Gràcies als seus consells, he après a posar un «cronòmetre» a cada petició per garantir que el meu scraper sigui realment autònom i eficient, estalviant-me hores d’espera innecessària davant de la pantalla si la connexió a Internet o el servidor fallen.
Prompt utilitzat
Com puc configurar un límit de temps màxim a cada petició del meu scraper perquè no es quedi esperant per sempre si una pàgina no respon?
4. Iteració i Co-programació amb IA per generar, millorar i documentar el codi
Encara que la IA m’ha generat el codi, hem fet diverses proves fins a arribar a la versió definitiva. He après que no es tracta de copiar i enganxar, sinó de corregir errors de funcionament que van sorgir durant la integració.
L’error del bloqueig (CORS): Al principi, el xatbot no podia respondre a la web per un error de seguretat del navegador. Vam haver d’afegir la llibreria CORS(app) perquè el servidor permetés rebre preguntes des del meu domini de l’institut.
from flask_cors import CORSL’error del port ocupat (Ngrok): Cada vegada que reiniciava el codi, em deia que el port estava ocupat. Vam afegir una línia (pkill -f ngrok) que tanca qualsevol connexió antiga abans de començar, evitant haver de reiniciar tot el Google Colab.
os.system("pkill -f ngrok")
time.sleep(1)Com m’ha ajudat la IA?
M’ha ensenyat a llegir els missatges d’error de la consola. Quan el programa fallava, jo li passava l’error a la IA i ella m’explicava quina línia s’havia de modificar. Això m’ha permès entendre la lògica de cada part del backend.
Prompt utilitzat
El servidor em dóna un error de port ocupat cada vegada que el vull tornar a engegar, com ho puc solucionar automàticament?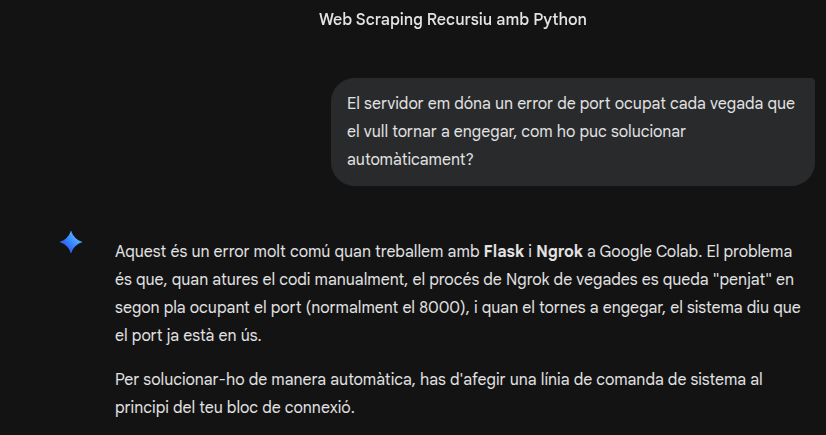
5. Documentació del Repositori
El projecte s’ha allotjat en un repositori de GitHub per gestionar les versions del codi. La documentació s’ha estructurat mitjançant fitxers en format Markdown per detallar el funcionament i l’evolució de la infraestructura.
L’estructura és vasa en 2 arxius, README i CHANGELOG.
README.md: Conté les instruccions tècniques de l’entorn, la llista de llibreries necessàries (google-generativeai, flask, pyngrok) i els passos per configurar les claus de l’API.
CHANGELOG.md: Registra l’ordre cronològic de les modificacions. Detalla el pas de l’scraper simple a la integració amb Flask i les correccions posteriors de seguretat.
Gestió de Commits: S’han realitzat pujades de codi fragmentades. Cada commit descriu un canvi específic, com la implementació del control de CORS o l’ajust del límit de caràcters per al context de la IA.
En la següent imatge es pot observar el repositori on es troben aquests 2 arxius a part de més arxius que son part del XatBot o ajuden al seu desenvolupament.
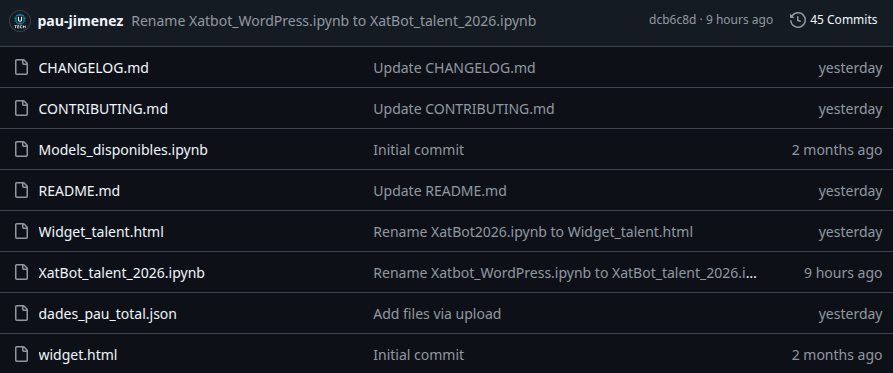
Última actualització de l’arxiu README .

# 🤖 Xatbot TalentFP 2026 - Pau Jiménez
Projecte de desenvolupament d'un assistent virtual intel·ligent basat en l'IA Gemini, adaptat per al portal de portafolis del centre i el projecte TalentFP.
# 🚀 Funcionalitats Principals
- **Scraping Recursiu:** Sistema d'extracció de dades automàtic que recorre tot el domini `pjimenez.inscastellbisbal.net`.
- **Base de Coneixement Dinàmica:** Generació automàtica de fitxers JSON amb el contingut actualitzat del WordPress.
- **Seguretat:** Gestió de claus d'API mitjançant Secrets de Google Colab (no exposades al codi).
- **Interfície Widget:** Integració mitjançant un Widget HTML personalitzat per a WordPress.
# 🛠️ Stack Tècnic
- **Llenguatge:** Python 3.x
- **Biblioteques de Scraping:** BeautifulSoup4, Requests
- **IA:** Google Gemini Pro via API Studio
- **Entorn:** Google Colab sincronitzat via OAuth amb GitHub
# 📂 Estructura del Repositori
- `XatBot_talent_2026.ipynb`: Quadern principal amb la lògica de la IA i el Scraper.
- `Widget_talent.html`: Codi del front-end per a la integració web.
- `dades_pau_total.json`: Base de dades extreta del WordPress.
- `CHANGELOG.md`: Historial de versions i millores.
- `CONTRIBUTING.md`: Normes de col·laboració i qualitat de codi.Última actualització de l’arxiu CHANGELOG.
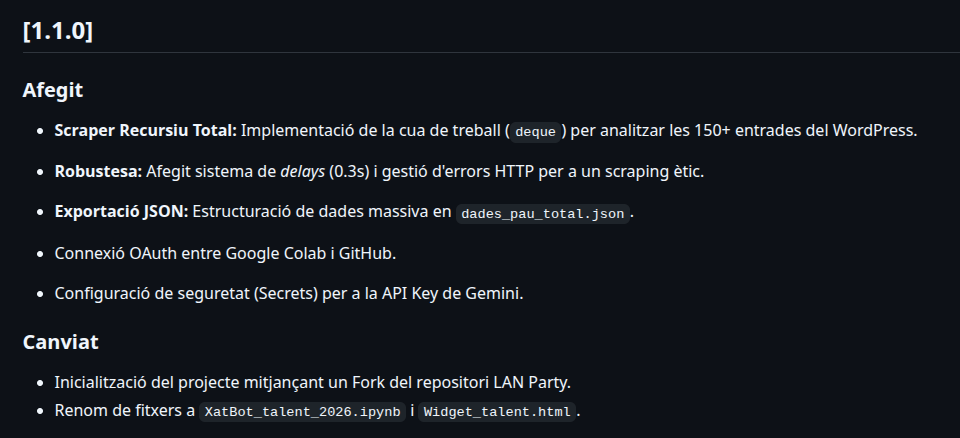
## [1.1.0]
### Afegit
- **Scraper Recursiu Total:** Implementació de la cua de treball (`deque`) per analitzar les 150+ entrades del WordPress.
- **Robustesa:** Afegit sistema de *delays* (0.3s) i gestió d'errors HTTP per a un scraping ètic.
- **Exportació JSON:** Estructuració de dades massiva en `dades_pau_total.json`.
- Connexió OAuth entre Google Colab i GitHub.
- Configuració de seguretat (Secrets) per a la API Key de Gemini.
### Canviat
- Inicialització del projecte mitjançant un Fork del repositori LAN Party.
- Renom de fitxers a `XatBot_talent_2026.ipynb` i `Widget_talent.html`.Com m’ha ajudat la IA?
Ha servit per estructurar els fitxers Markdown seguint els estàndards de documentació tècnica. Ha facilitat la redacció de les versions del CHANGELOG, categoritzant les millores de l’scraper i del servidor per mantenir un registre clar de l’evolució del programari.
Prompt utilitzat
Ajudem a redactar l'estructura per un fitxer README i CHANGELOG sobre el que acabem de treballar pel meu repositori de GitHub. Ha de ser en Markdown.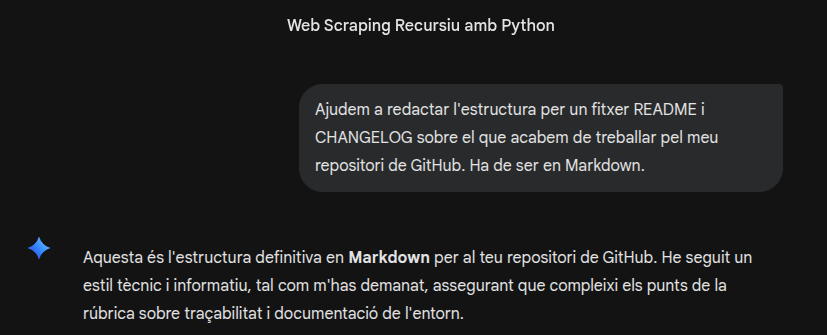
Deixa un comentari